9.4. Sigmoid & Approximation
Warning
This activation function has an asymptote to negative \(y\) infinity and positive y infinity outside of a very small safe band of input \(x\) values. This will cause nan and extremely large numbers if you aren’t especially careful and keep all values passed into this activation function within the range -4 to 4 which is its golden range. Think especially carefully of your initial weights, and whether or not they will exceed this band into the danger zone. See: \sigma_a(x)
To be able to use (fully homomorphically encrypted) cyphertexts with deep learning we need to ensure our activations functions are abelian compatible operations, polynomials. Sigmoid (1) is not a polynomial, thus we approximate (3). Similarly since we used an approximation for the forward activations we use a derivative of the sigmoid approximation (4) for the backward pass to calculate the local gradient in hopes of descending towards the global optimum (gradient descent).
9.4.1. Sigmoid \(\sigma(x)\)
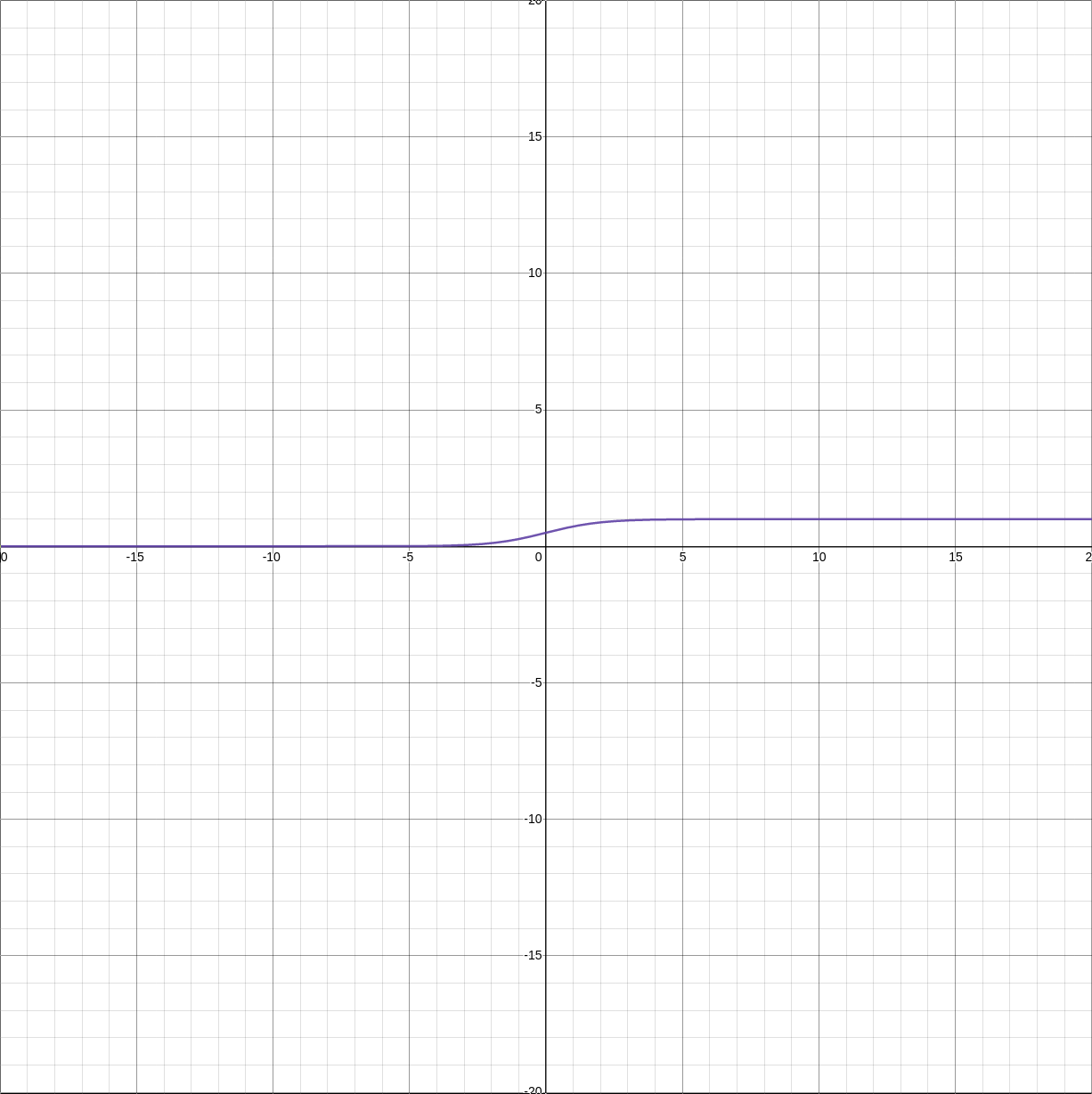
9.4.1.2. \(\frac{d\sigma(x)}{dx}\)
(2) Sigmoid derivative (Andrej Karpathy CS231n lecture)
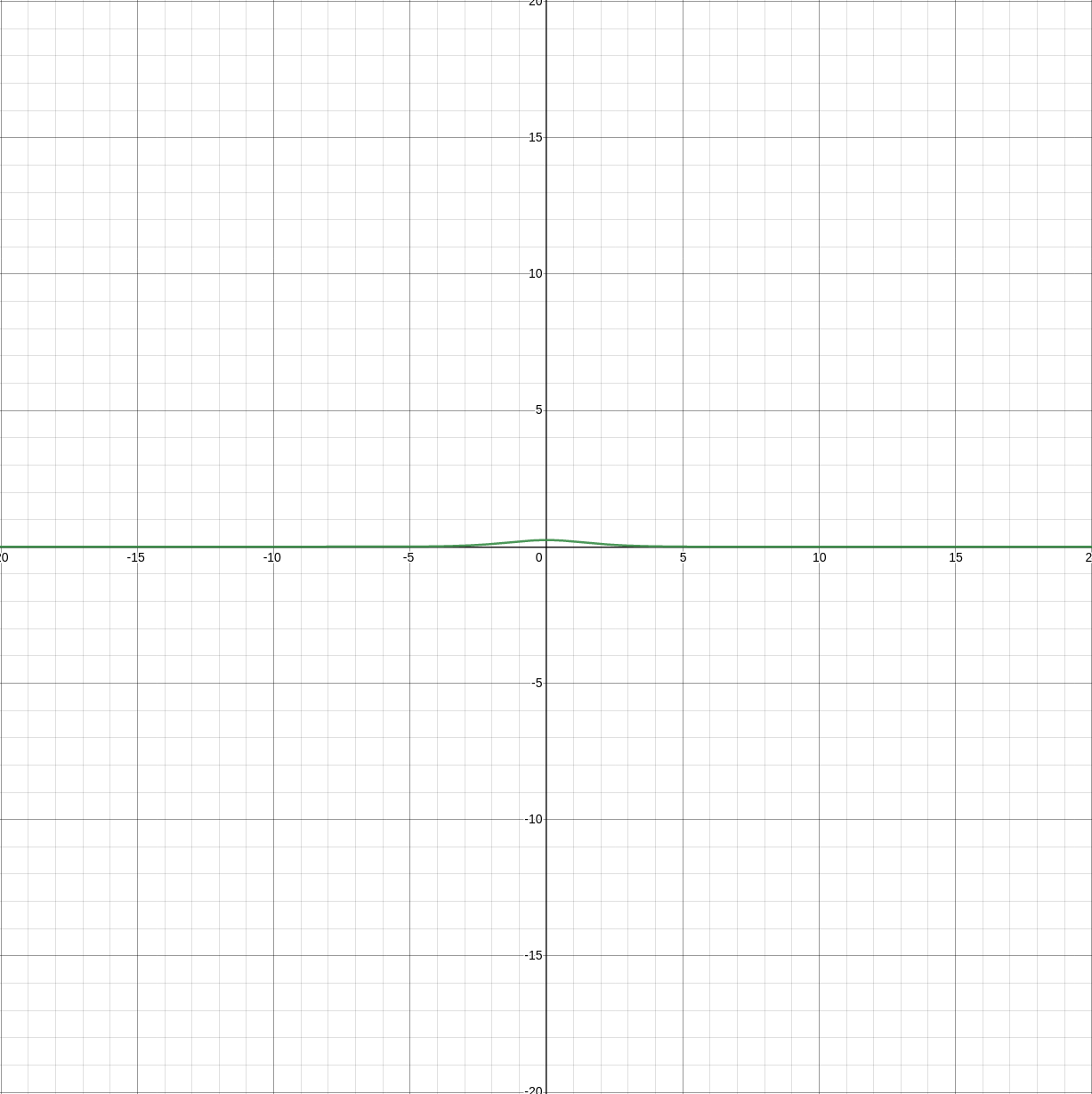
9.4.2. Sigmoid-Approximation \(\sigma_a(x)\)
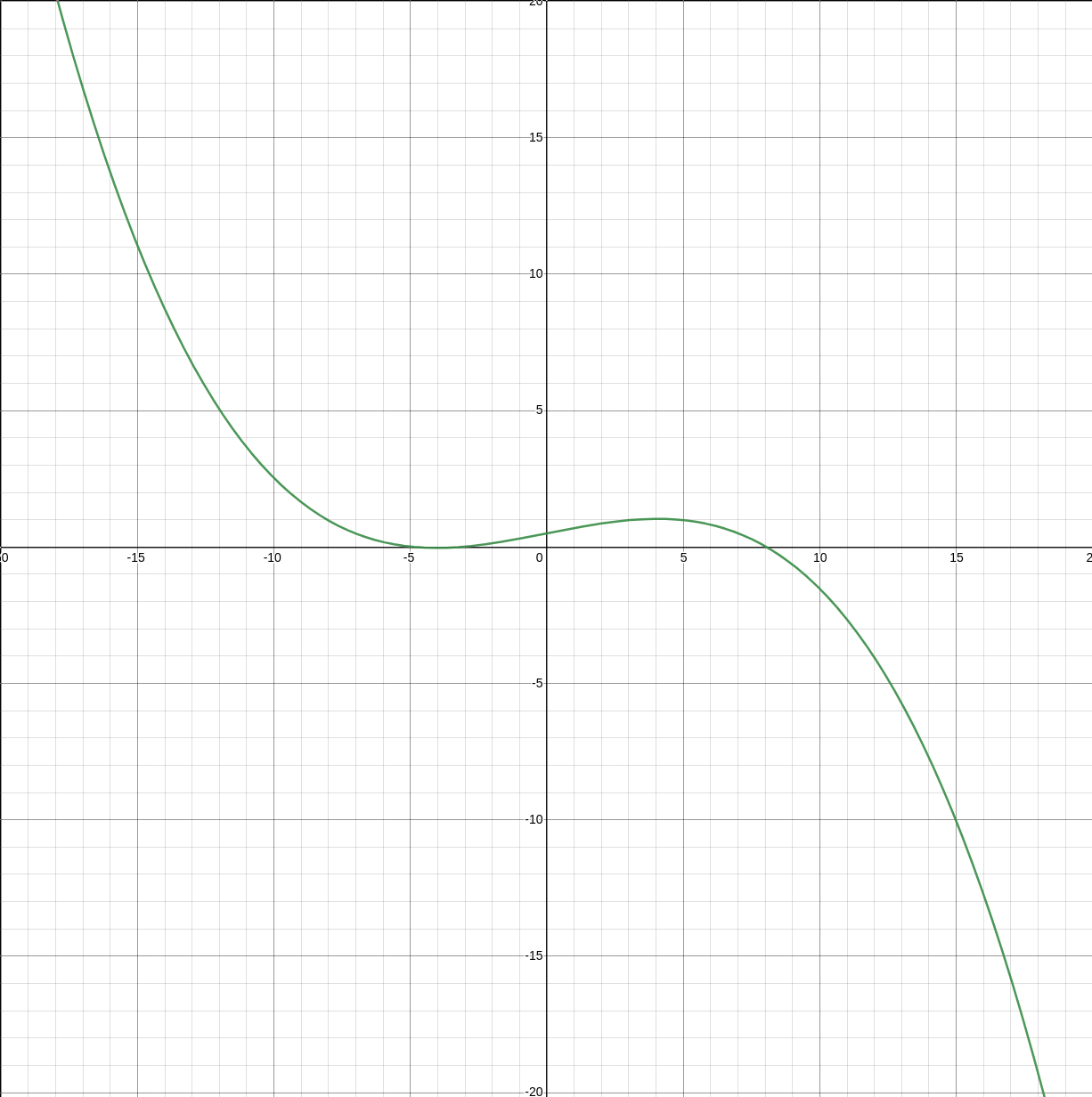
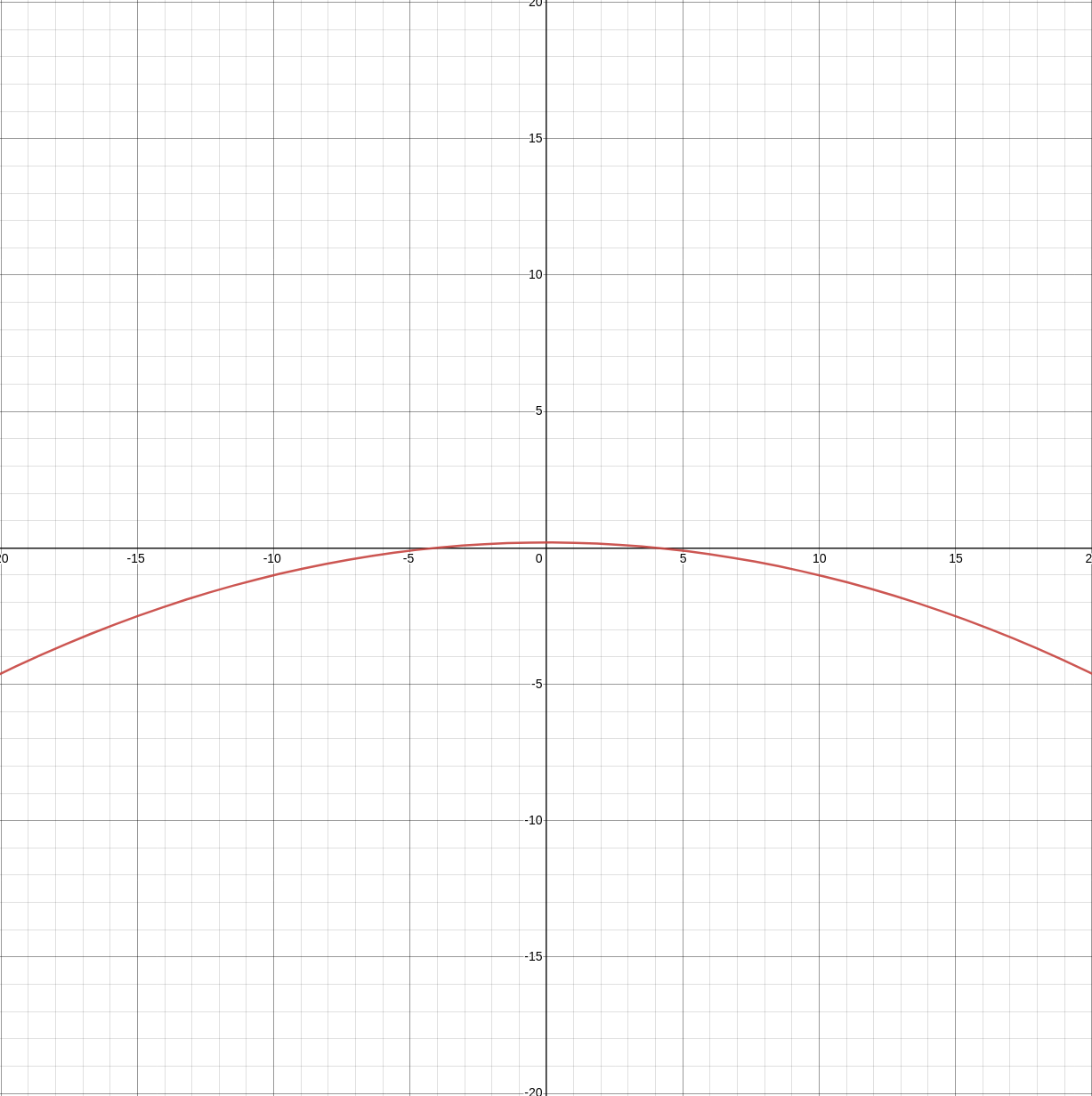
9.4.3. Sigmoid API
Note
You may see some or no content at all on this page that documents the API. If that is the case please build the documentation locally (Docker Build), or view this documentation using a “autodoc”-ed version of this documentation (see: Documentation Variations).
- class fhez.nn.activation.sigmoid.Sigmoid
Sigmoid approximation.
- backward(gradient: numpy.array)
Calculate gradient of sigmoid with respect to input x.
- property cost
Get computational depth of this node.
- forward(x)
Calculate sigmoid approximation while minimising depth.
- sigmoid(x)
Calculate standard sigmoid activation.
- update()
Update nothing, as sigmoid has no parameters.
- updates()
Update nothing, as sigmoid has no parameters.